21
2.2●データベースのコピーの仕組み
ネイタルデータのコピー機能は普通のファイルコピーとは異なり、次のような特徴があります。
①同じフォルダ内にコピーできない。
②別の名前にリネームしてコピーできない。
③ネイタルデータを複製などしていない。
③が重要なので詳しく説明します。今ここでTEST1とTEST2というフォルダを用意し、TEST1に「あまてる子」というネイタルデータを用意したとします(図1)。これをTEST2にコピーします。そしてTEST2のフォルダにコピーされた「あまてる子」のデータを編集して「みちてる子」に変更したとします。 次にTEST1のフォルダを開くと、こちらも「みちてる子」に名前が変更されています(図2)。 良く知られたファイルコピーではこのように両方とも変更されてしまうことはありえません。アマテルのネイタルデータのコピーは、データを複製するのではなく、任意のフォルダ(複数でも可)に、ネイタルデータのIDを登録することなのです。
コピーの内部的な仕組み
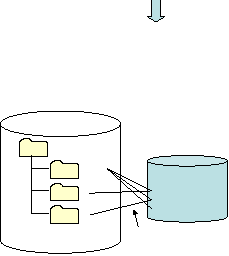
ネイタルデータが新規登録されるときは、ユニークIDを与えられネイタルデータ記憶庫に登録されます(図3)。あまてる子のデータがID15番を与えられ登録されたとします。(番号は自動的に割り当てられます。)
そのIDがどのフォルダに存在しているかを管理しているのがフォルダツリー記憶庫です。先の登録の際に、フォルダTEST1にはID15が登録されました。次にTEST2にID15がコピーされました。TEST1、TEST2共にどちらのフォルダをひらいてもあまてる子が存在します(図1)。 そしてどちらのフォルダであっても、あまてる子のデータを編集するとき、ID15番のデータが編集対象となります。TEST1であれTEST2であれ、あまてる子のIDは15番で、そのIDのデータを編集すると、どちらのフォルダからみても編集結果は同じです。

あまてる子
あまてる子
コピー

これを編集して
「みちてる子」にすると

両方とも「みちてる子」
になってしまう。





TEST1
TEST2


みちてる子
みちてる子





TEST1
TEST2
なぜそのようになっているか?
たとえば有名人データは、職業別に階層フォルダで整理されています。検索によって星座別にこれらの人物を仕分けしたくなったとしましょう。牡羊座の人を検索で抽出し、それを牡羊座のフォルダにコピー。次は牡牛座、次は・・・と、コピーをくりかえしていったとき、ファイルコピーのような実体コピーだと、膨大なリソースを消費することになってしまいます。登録されているデータはそのままに、フォルダツリーの位置の情報だけをコピーしていけば効率的です。 つまり多量のデータでも遠慮なくコピーしてフォルダ単位で仕分けをして、整理と分析を大胆に進められるようになっています。
一部の例外(※)を除き、実体コピーの機能はありません。人物も出来事も生来的にユニークなものであるはずだからで、重複登録は極力避けるべきものだというのが設計方針です。
図1
図2
ネイタルデータ記憶庫
ID15 あまてる子
ID16 みちてる夫
ID17 あまてる太郎
TEST1
TEST2
TEST3
15,16,17
16
15
フォルダのツリー構造と、どのフォルダにどのIDが入っているかを記憶している。
ROOT
フォルダツリー記憶庫
図3
二つの記憶庫間に張られたシンボリックリンク
あまてる子が、複数のフォルダに顔を出していても、編集されるのはただ一つの実体データです。そしてすべてのフォルダのあまてる子が更新されます。これは欠点ではなく利点です。
※回帰時期検索などで動的に生成される出生データがDBにコピーされるときなど。